多模型数据库的理念是:给你提供了一种多视图查看数据的能力。ArangoDB 的数据库背后的理念是:可以自由的将这些视图组合到单个查询中。在 ArangoDB 3.4 的更新中,我们进一步的扩展了 ArangoDB 的这些功能。对于每次发布 ArangoDB 的新版本,我们总是感到很兴奋,但是,这次发布的版本有点特别。新版本包括两个新特性:一个是基于 C++ 的全文搜索和排序引擎,我们称之为:ArangoSearch;另一个是通过集成 Google™S2 Geometry Library 和 GeoJSON,极大的扩展了地理空间查询的功能。加入 ArangoSearch 和 GeoJSON的网络研讨会来更加深入的了解这些新特性。
ArangoDB 3.4 版本在各个方面的的性能也获得了提升,例如改进了在多核心机器中运行的性能和可扩展性。测试结果显示,ArangoDB 3.4 查询性能在多核心机器上比原来提升了 100%
本次版本更新除了 40 多项改进,让我们一起来看一下这些新特性.
ArangoSearch
全文搜索&相似度排名引擎。
ArangoSearch 是集成到 ArangoDB 中基于 C++ 搜索和排名引擎。ArangoSearch 允许你将搜索和 ArangoDB 其他的访问模式相结合。
搜索使用特殊类型的具体视图,一次性提供了跨多个集合的全文搜索。在视图类型 arangosearch 的定义中,您可以使用一个或多个通用文本分析器指定由倒置索引覆盖的整个集合或单个字段。视图的概念在 ArangoSearch 中是独有的,更多的普通视图(例如:SQL 视图、materialized 视图)可能在后面的 ArangoDB 版本中陆续介绍。
ArangoSearch-视图的概念:
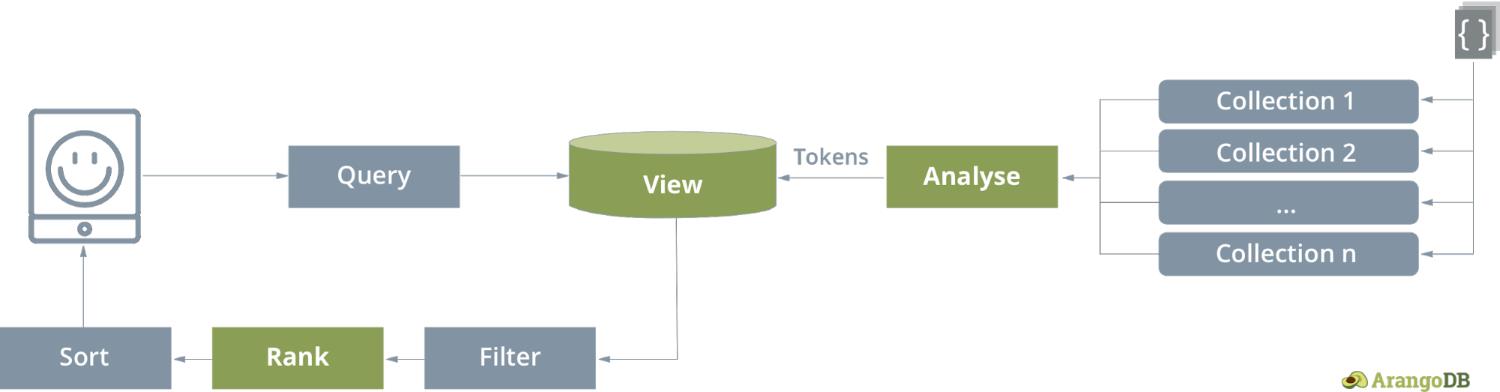
在本版本中,ArangoSearch 包括以下功能:
基于相关性的匹配
短语和前缀匹配
使用布尔值进行复杂搜索
相关运行时调优
搜索查询与所有数据模型和访问模式的均可完美组合
ArangoSearch 不单单是一个搜索引擎,而且还是一个相似度排名引擎。我们集成了两种排名算法(例如:BM25 and TFIDF),你可以对结果进行排名或者提升某些查询参数,以微调搜索结果的相关性。此外,这个版本的 ArangoSearch 已经包括了12种语言的解析器,包括:英语、汉语、德语、西班牙语、芬兰语、荷兰语等等。
将 ArangoSearch和 ArangoDB’s 图形数据功能相结合,可以很好加强在其欺诈检测、知识图、语义搜索的应用,甚至在基因组数据的医学行业都有很好的用例。
ArangoSearch支持集群,可以用于超过单台机器的数据集。在设置集群是,协调器始终负责查询规划、优化和执行,将传输的查询数据引导到正确的 DBServer 以在本地处理查询。使用此体系结构,可以针对驻留在不同计算机上的数据执行更加高效的搜索查询。

我们希望你会发现 ArangoSearch 是 ArangoDB 功能非常有用的拓展功能。
了解更多关于搜索的新功能请查看ArangoSearch 教程 或者根基您的知识能力查看 ArangoSearch 的架构。
完整的 GeoJSON 支持和 Google S2索引
我们想强调的另外一点是 ArangoDB 在地址位置应用诸多提升。ArangoDB在很久以前就支持了点和距离的简单地理查询。随着 ArangoDB 3.4 发布和 GeoJSON 的支持,你现在可以有构建基于地理位置查询的高精度应用。
GetJSON的支持包括所有的原始地理信息例如:多点信息、多边形信息和很多处理地理位置信息的相关方法例如:GEO_DISTANCE、GEO_CONTAINS、GEO_EQUALS和GEO_INTERSECTS。当然,你可以将这些新得地理空间功能与所有支持的数据模型以及ArangoSearch 的功能相结合。
你可以通过 GeoJSON 教程来试一试。
地理信息查询的结果会通过一个小插件`OpenStreetMap`显示出来,这有助于快速查看浏览结果。
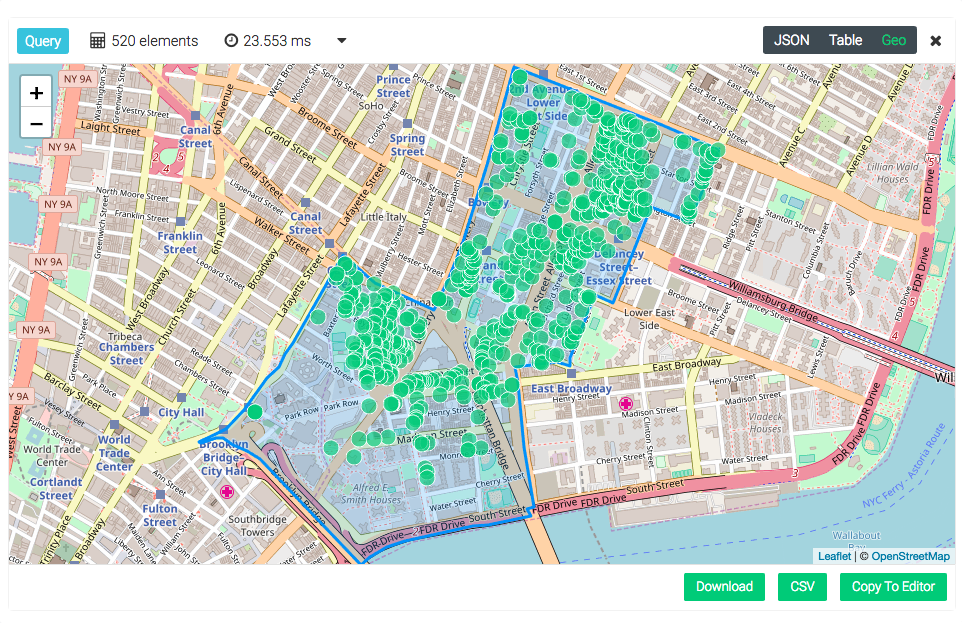
新的查询分析器
优化复杂的查询可能非常耗时。为了优化这个过程,我们创建了一个 AQL 的查询分析器。AQL 查询分析器显示完整的查询配置文件,包括有关在查询的每个阶段中花费的时间的详细运行时的系统信息。使用新的 AQL 查询分析器,你可以通过添加索引,重新构建查询或优化数据结构,对潜在的优化做出明确的决策。显示的执行计划包括三个新列:
调用,每个查询阶段执行的次数;
项目,给定阶段的临时结果行数;
运行时,本次活动中上花费的总时间。
可以通过`db._profileQuery()`或单机 WebUI 的 「查询」选项卡中选择「配置文件」按钮在 shell 中使用查询分析器。
想了解更多查询优化和分析器的更多信息请查看 AQL 查询分析器教程
与 "Explain" 命令想法的是,"Profiler"执行查询并显示 AQL 每个步骤与实际实际的时间花费。我们希望在这样操作有助于简化查询优化。
查询分析器输出信息(控制台):

查询分析器输入信息(WebUI)

新的流式游标
在过去的几个月中,我们收到了很多需求,这些需求希望能够在查询很多数据时,寻求一种响应时间更快的方法。为了这些需求,我们在 ArangoDB 中添加了流式游标。通过使用流式游标,你可以在服务器上获取计算的结果;你没有必要等待查询结果完全执行,这样用户就可以更快的看到显示结果。此外,使用流式游标查询的数据要比使用内存查询的更大。
集群体验提升
在过去的几年中,我们改进并且丰富了 ArangoDB 的集群功能。虽然我们知道这个功能不是很完美,但是他并没有阻止我们在每个版本中对其进行改进。 如果你使用 ArangoDB 的集群功能并且升级到的 3.4 版本,你将体会到关于集群的最新功能。
本次功能的改进后,集群中可以防止不必要的行为,还是可以更快的实现集群启动,更快的同步、和更快的进行数据查询。彻底优化了内部协议和请求处理:Distributed Collect 只是集群范围查询中的例子。
对于 3.4 版本,我们对于集群的内部进行了彻底的优化,以便于更好的维护鼓掌转移和集合管理。这样做导致某些情况下的稳定性提高,操作更块。
此外,使用最近发布的 ArangoDB Kubernetes 运算符,在 k8s 中部署 ArangoDB 只需要一行简单的命令 kubectl apply -f cluster.yaml 。剩下的操作会被 k8s 和 ArangoDB 运算符自动完成。
在服务不中断的情况下,升级部署只需要更改 YAML 文件中的 Docker 镜像名称即可。
想要了解更多关于 ArangoDB Kubernetes 操作符 的相关操作请查看 快速入门
默认数据存储引擎是 RocksDB
新安装的 ArangoDB,从 3.4 版本开始将 RockDB 作为默认的数据存储引擎,如果你从以前的版本升级到 3.4 版本,ArangoDB的引擎将会和你以前的版本设置的一致。我们在优化 ArangoDB 中集成的 RocksDB 投入了大量的工作,使其可以更快,并且扩展在配置方面的其他可能性.相关重要的改进如下:
优化二进制存储格式:新格式针对 RocksDB 进行了优化,新安装的 ArangoDB 默认采取这种格式。 新格式的一个主要优点是大大提高了数据插入性能。
可选缓存:用户现在可以给每个集合指定一个新属性 cacheEnabled 来定义要在内存中缓存的文档和主索引值。这种改进使得在多种情况下,性能将得到显著提升,特别是在点查找方面。
减少数据拷贝时间:针对自动故障恢复、集群和 DC2DC 设置提供了更好的体验。
我们已经进行了许多优化,使我们的 RocksDB 集成成为默认的存储引擎。我们相信你们也会很喜欢他。
总之,ArangoDB 3.4提供了40多个优化和改进。我们希望每个人都能从新版中获得新的体验。
原文链接:https://www.arangodb.com/2018/12/arangodb-3-4-full-text-search-geojson/