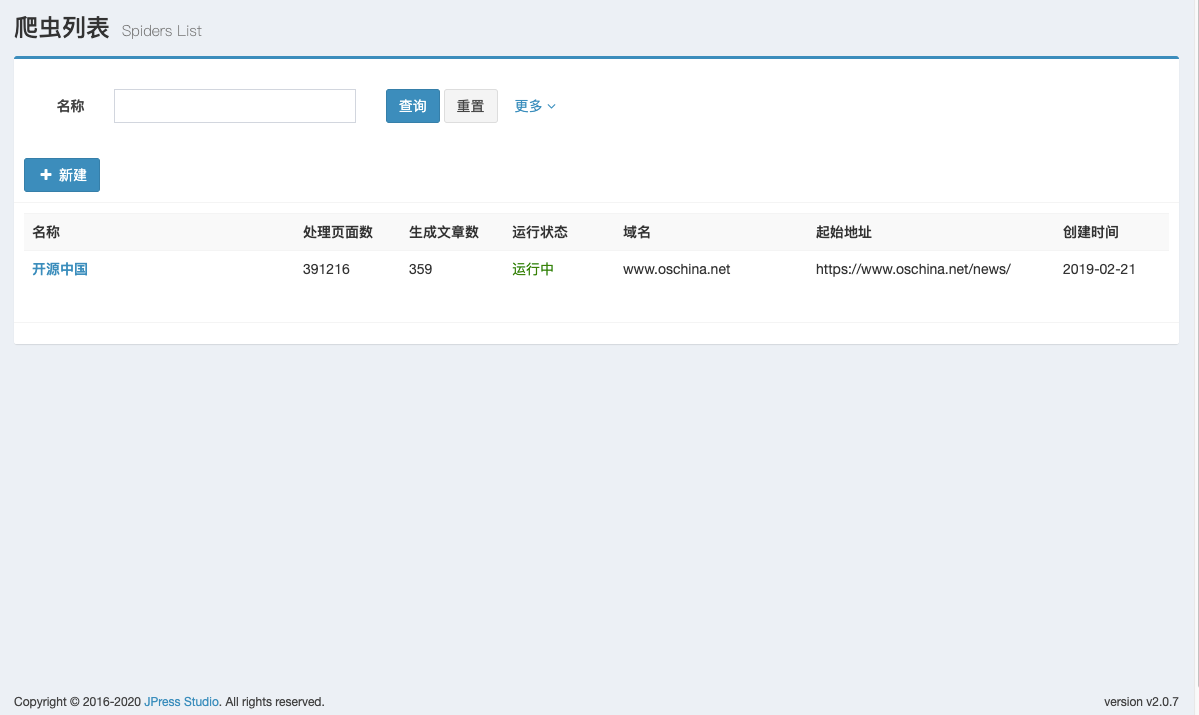
微软的 PowerToys 正在开发新的 OCR 文字识别功能,允许用户从图像中提取文本。
消息来源于 PowerToys 的 GitHub PR “[WIP] [New PowerToy] Create new OCR PowerToy #19172”
此 PR 引入了一个新的 PowerToy OCR 功能,通过选择矩形区域、单击单词或右键单击图像文件并选择 PowerOCR,可以在屏幕上的任何位置执行文字识别。
截至 7 月的第一周,要让这个 PowerToy 功能成熟还有很多工作要做,欢迎拉取和构建这个工具,大部分代码都是从我的存储库 Text Grab 复制的。
目前该 OCR 的基本功能已经搭建完毕,这是来自 PR 的演示:
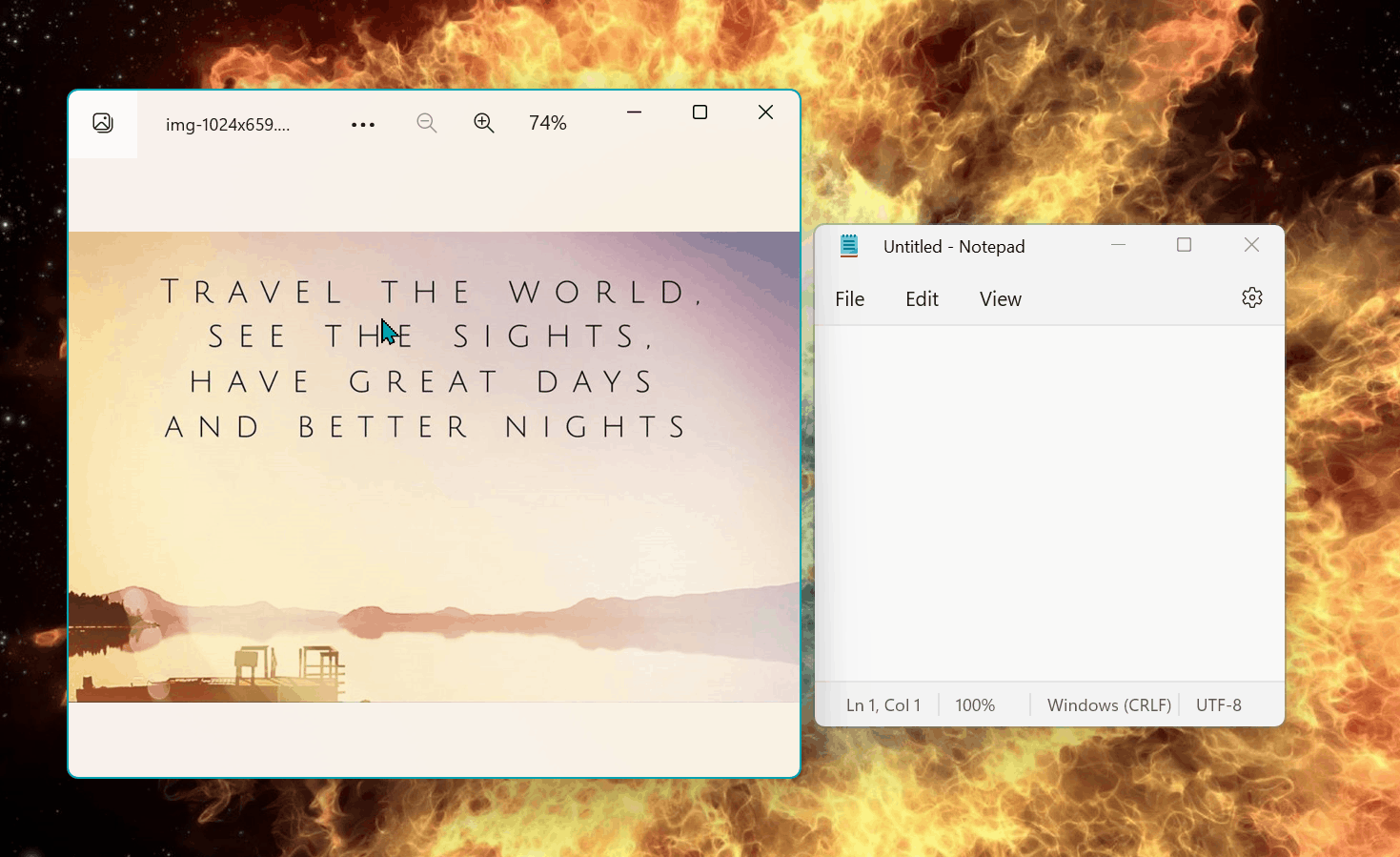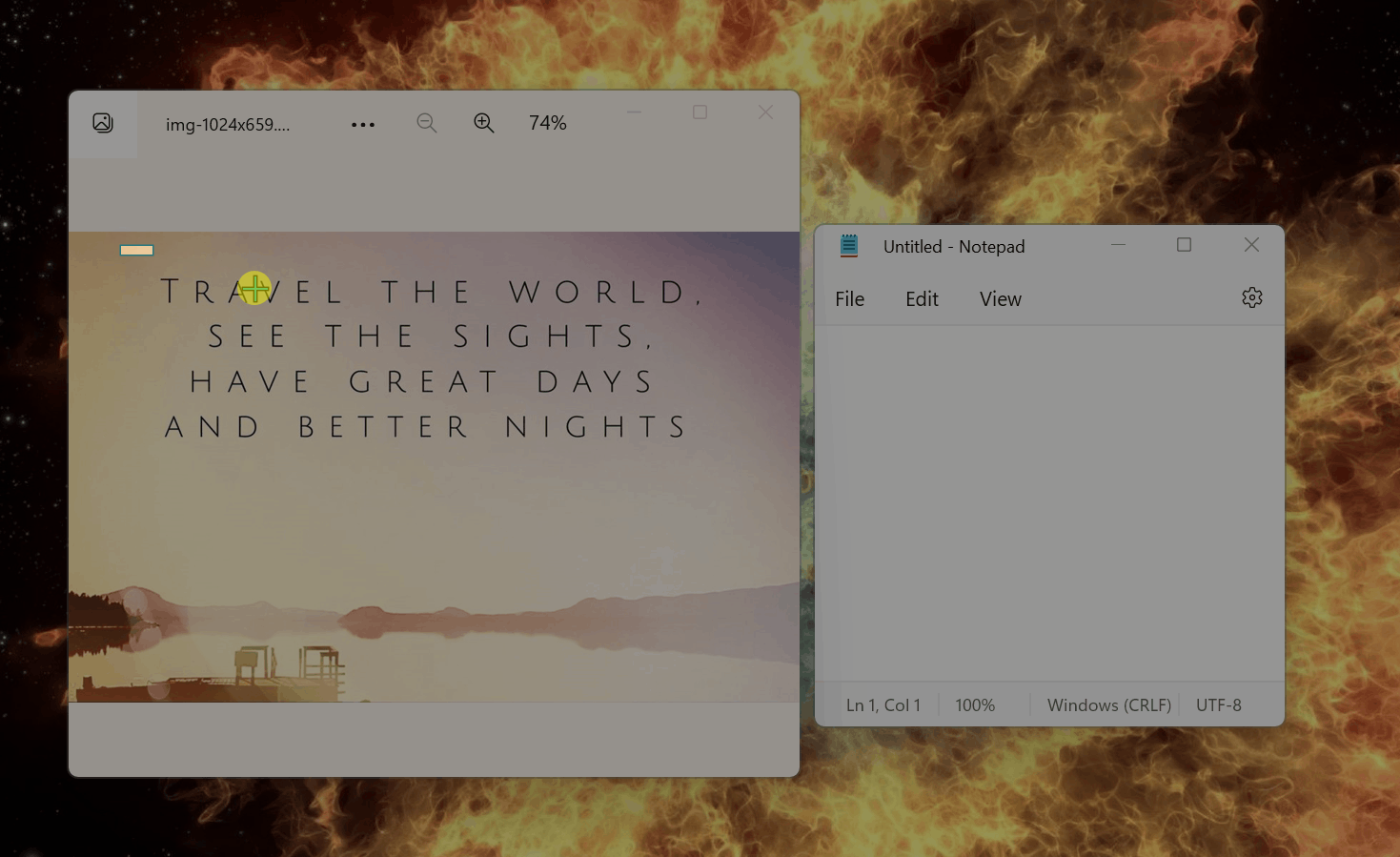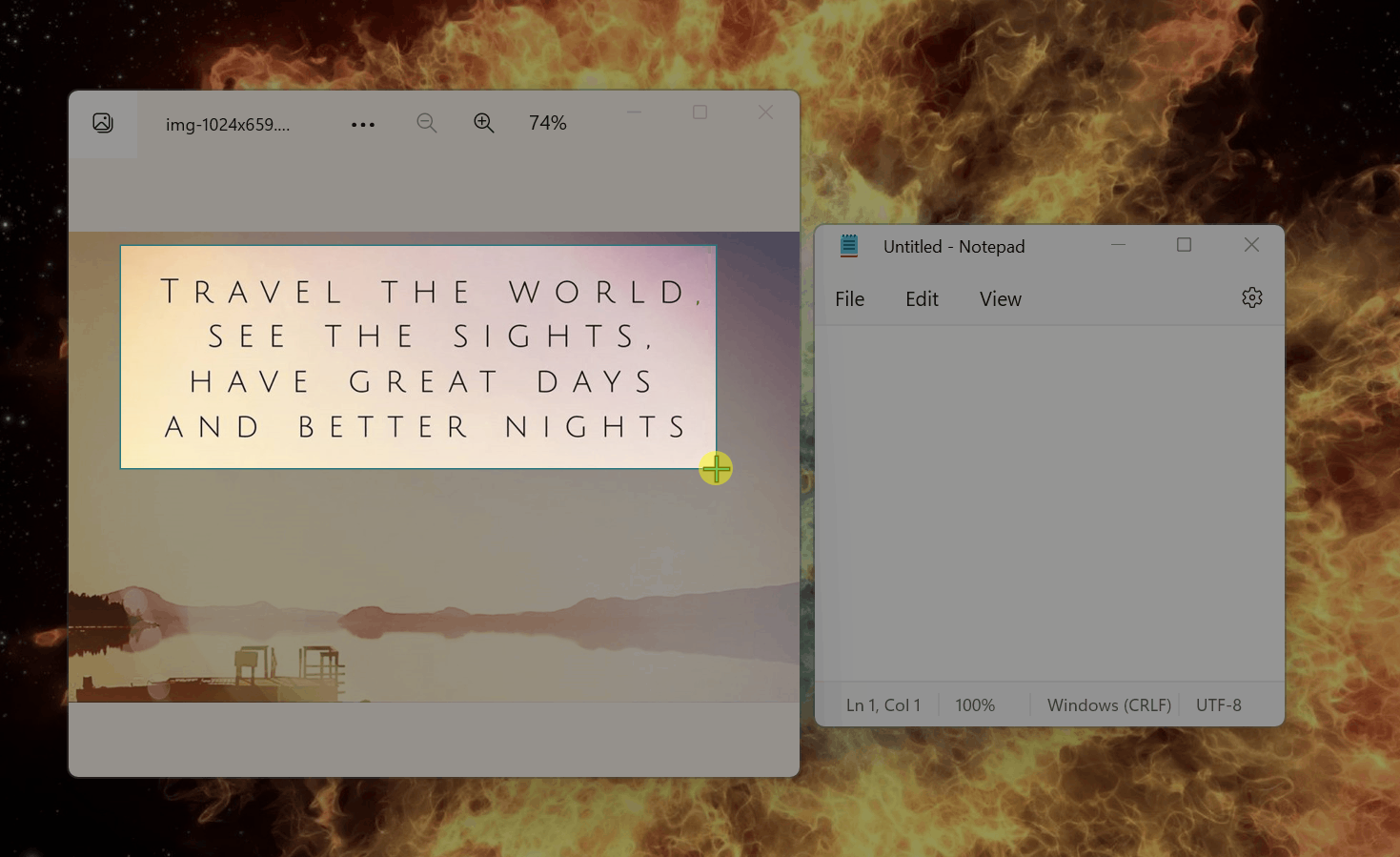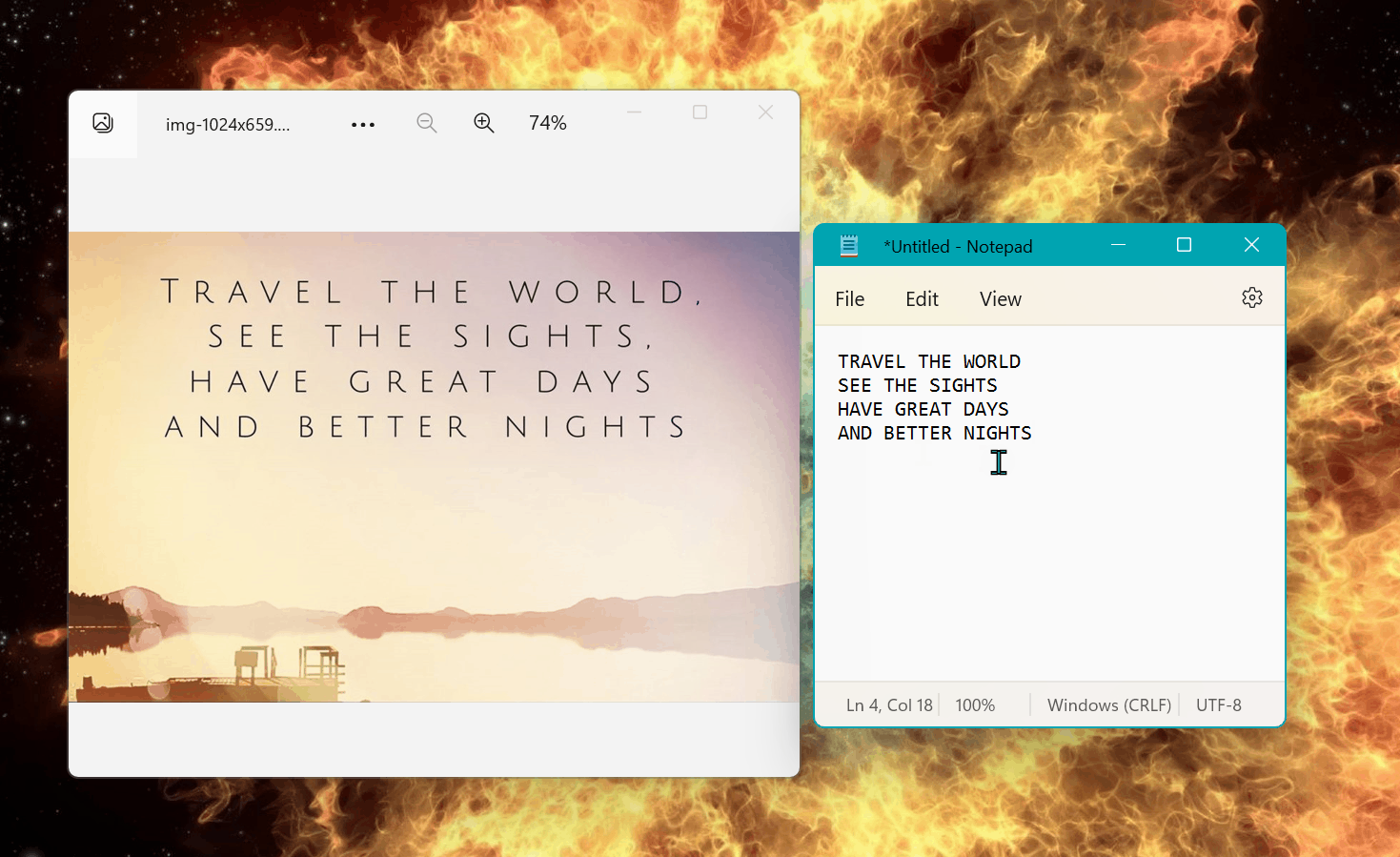
可以注意到,基本的英文 OCR 功能已完成,但距离一个成熟的功能还有太多事情要做,比如现在选取完毕后默认识别,没有右键单击的选项,也无法调整选区。此外,识别稀疏的英文非常简单,任何一个 OCR 工具都能做到,能否识别其他复杂场景,比如排版紧凑的中文,带有艺术字体的文本...这些才是 OCR 工具的开发难点。
目前来看,这项工具还需要大量开发工作,现在的情况是:
- 已添加设置页面
- 已完成多屏幕兼容测试
- 光标捕获测试即将完成
- 安装程序未完成
- 文档教程未完成
- PowerOCR 的图标等 UI 资产未完成
目前该功能还处于早期阶段,期待下一步的工作。
最后修改于 2022-08-19 15:51:16